
Naver Corp, 2021. 1. ~ Current
Project Summary
Although it varies by search system, almost 50% of search queries have no search results. These noresult queries hit search engine servers of all shards and consume system resources. This phenomenon becomes much harder when a search service has little documents.
If we can predict whether a query has search results in advance and forward the traffic only when search results exist, we can save the search engine resources a lot. Considering that the search engine servers occupy most of the search system, this is a good way to reduce the infrastructure cost.
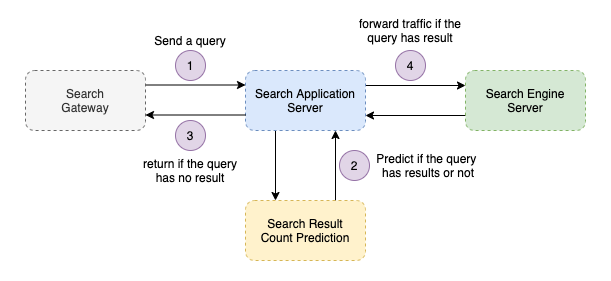
We built the structure like above and started to research about how to predict whether a query has search results or not precisly and efficiently.
Role
- Researched and implemented the prediction model.
- Conducted extensive experiments to prove infrastructure saving effects.
- Built data processing, model training and serving pipeline.
- Developed go package which trains naive bayes model using multi cores.
Model
Predicting whether a query has search results can be seen as a text binary classification problem. There were lot of model candidates like deep learning, decision tree and so on. But I selected naive bayes for the following reasons.
- Order between terms does not affect the presence of search results.
- Vocabulary size is so huge that training embedding vectors for every term might be ineffective.
- The goal is reducing infrastructure cost. So training and serving cost should be low.
I skipped the mathmatical details here. I checked the naive bayes model fulfilled the requirements of accuracy well through extensive experiments for many search services. In addition, the naive bayes model inference requires only key-value read so it was easy to serve.
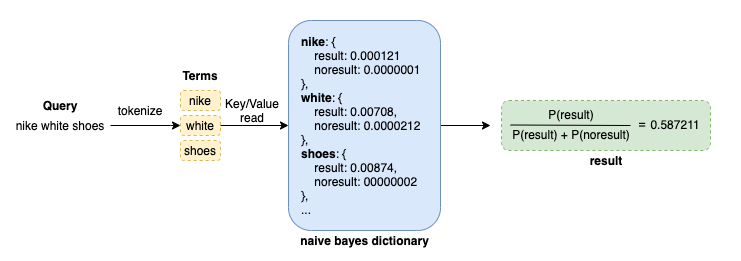
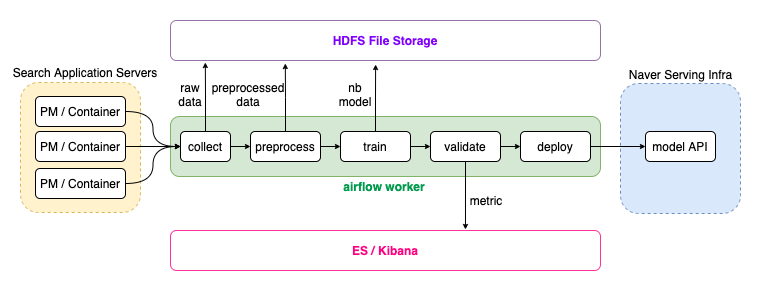
Pipeline
To serve srcp models into production search services, we needed a pipeline to continuously update the naivebayes models and track performance of them. So I designed pipelines using airflow.
Results
- The performance of the srcp model depends on which search service to be applied and how much threshold value is set.
- However, the overall performance of the model is similar like below.
- It was impressive that it could reduce the cpu utilization quite much.
| threshold | traffic reduction | cpu utilization reduction | FN ratio |
|---|---|---|---|
| 0.1 | 30% | 20% | 1% |
| 0.5 | 55% | 30% | 10% |
Limitations
Altough SRCP models can reduce the traffic significantly, there’re always risks of false negative cases. If the model predicts that a query has no search results but in reality there are search results, the user will not see the search results. For some sensitive services like shopping seardch, this can leads to serious problem. So we have tried to solve it in multiple ways.
- Conservatively set criteria for determining that there are no search results.
- Add additional key/value dictionary for import queries that should return search results.
- Skip prediction for long tail queries.
- Build a feedback loop to continuously improve accuracy of the model.
- Currently, I’m trying to reduce false negative cases with the ensemble of those methods.
Tech Stack
- Infrastructure: Linux(centos7), Docker
- Pipeline: airflow
- Language: go, python, shell script